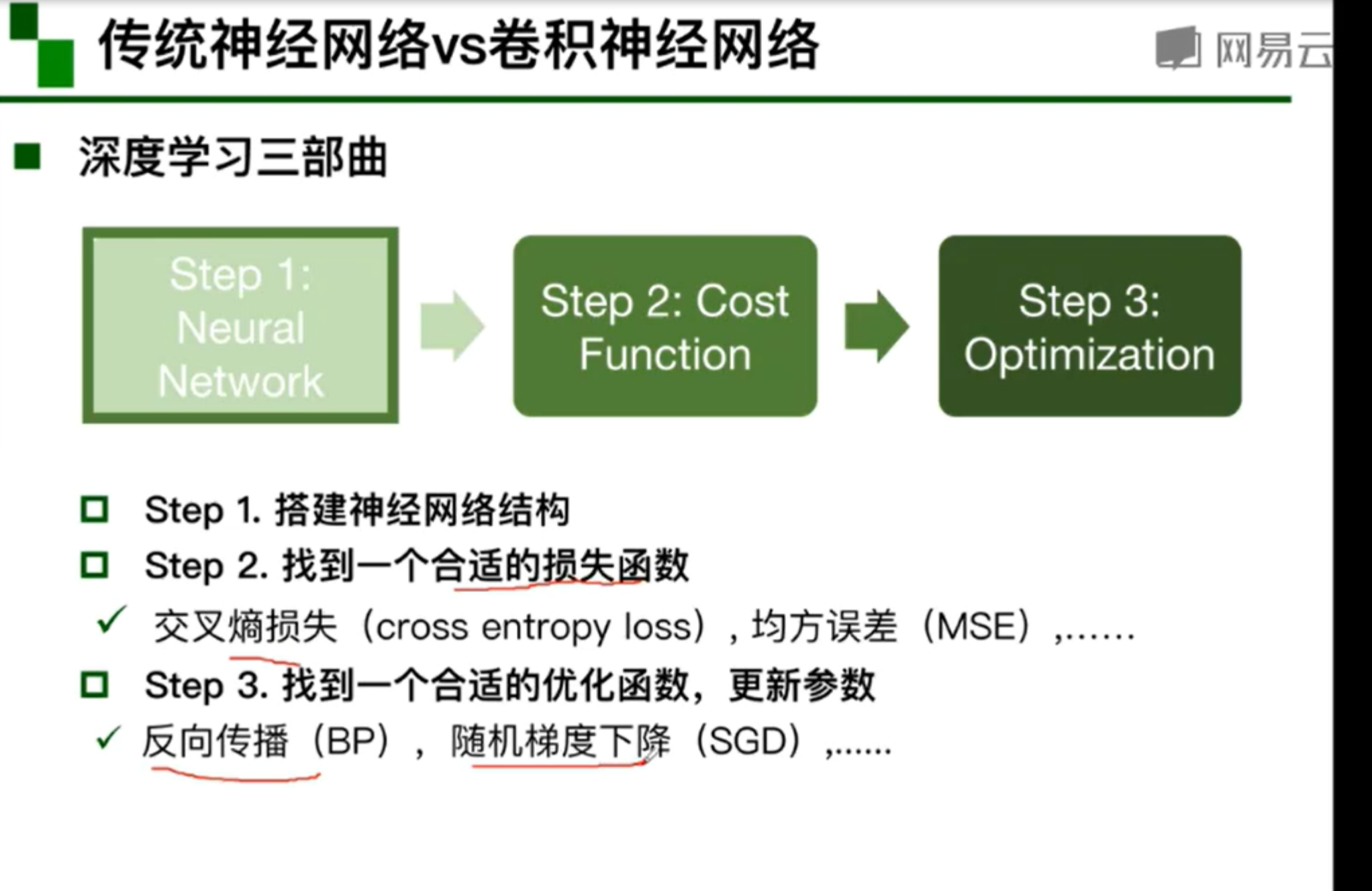
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
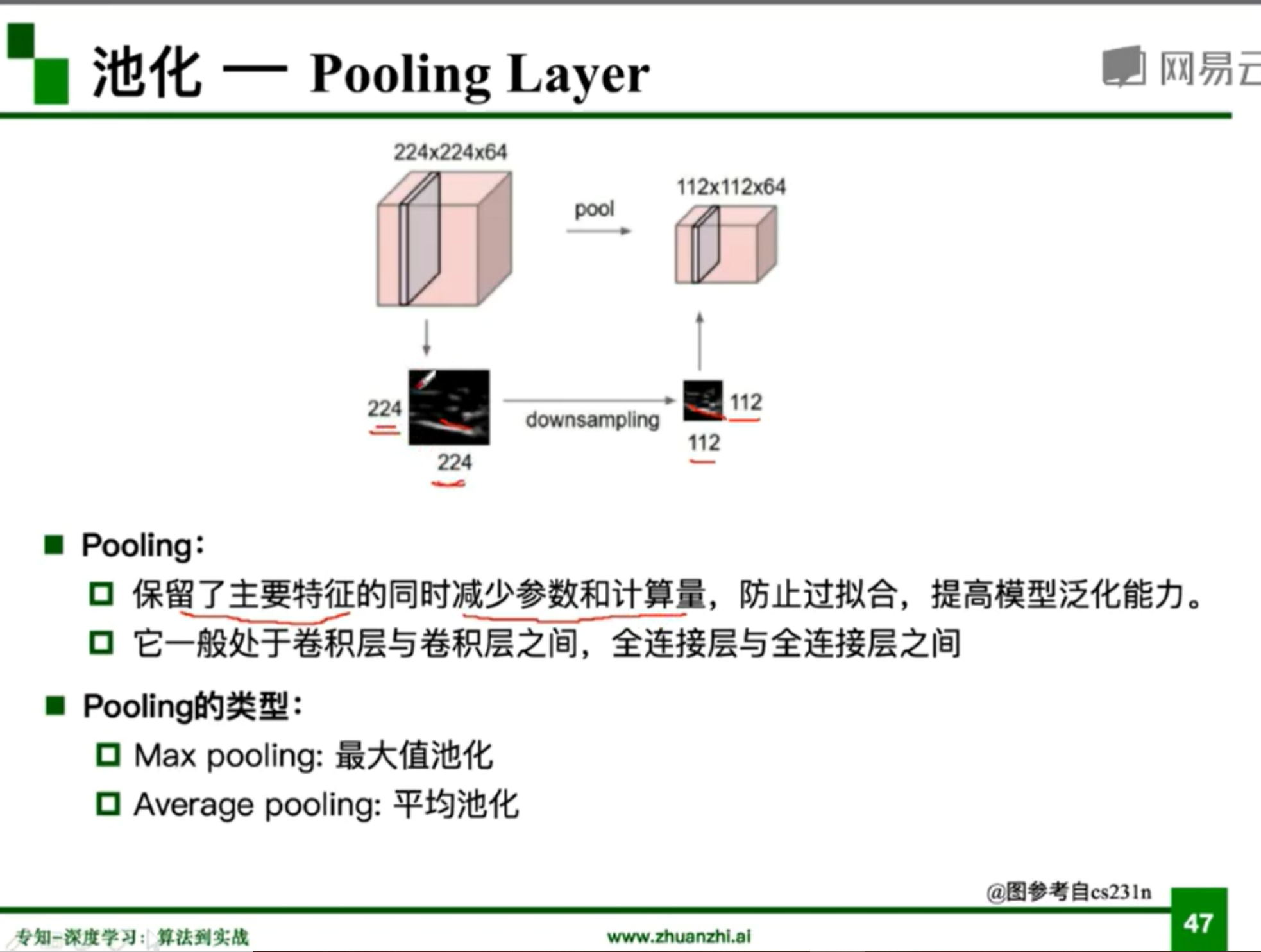
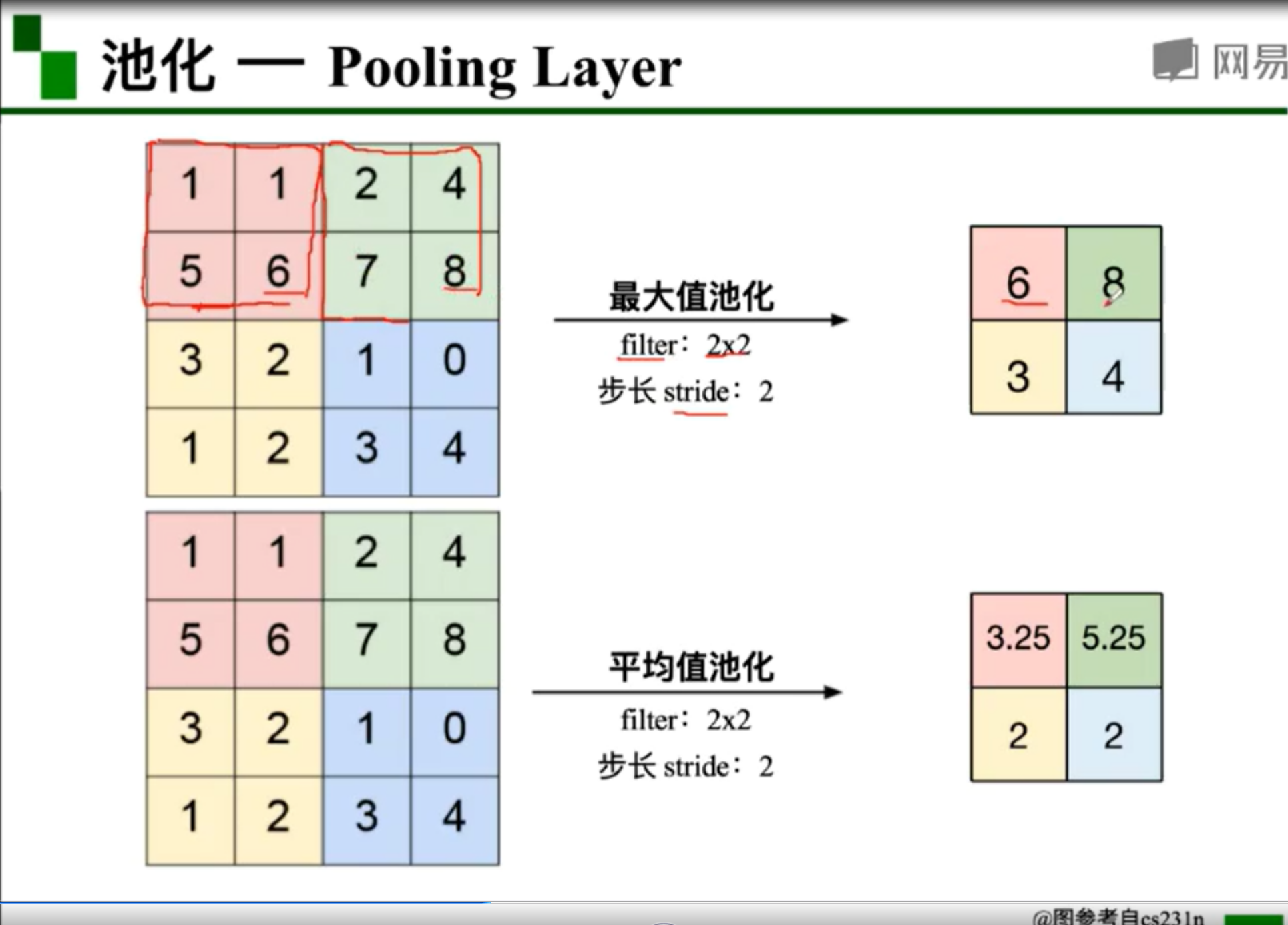
47
48
49
50
51
52
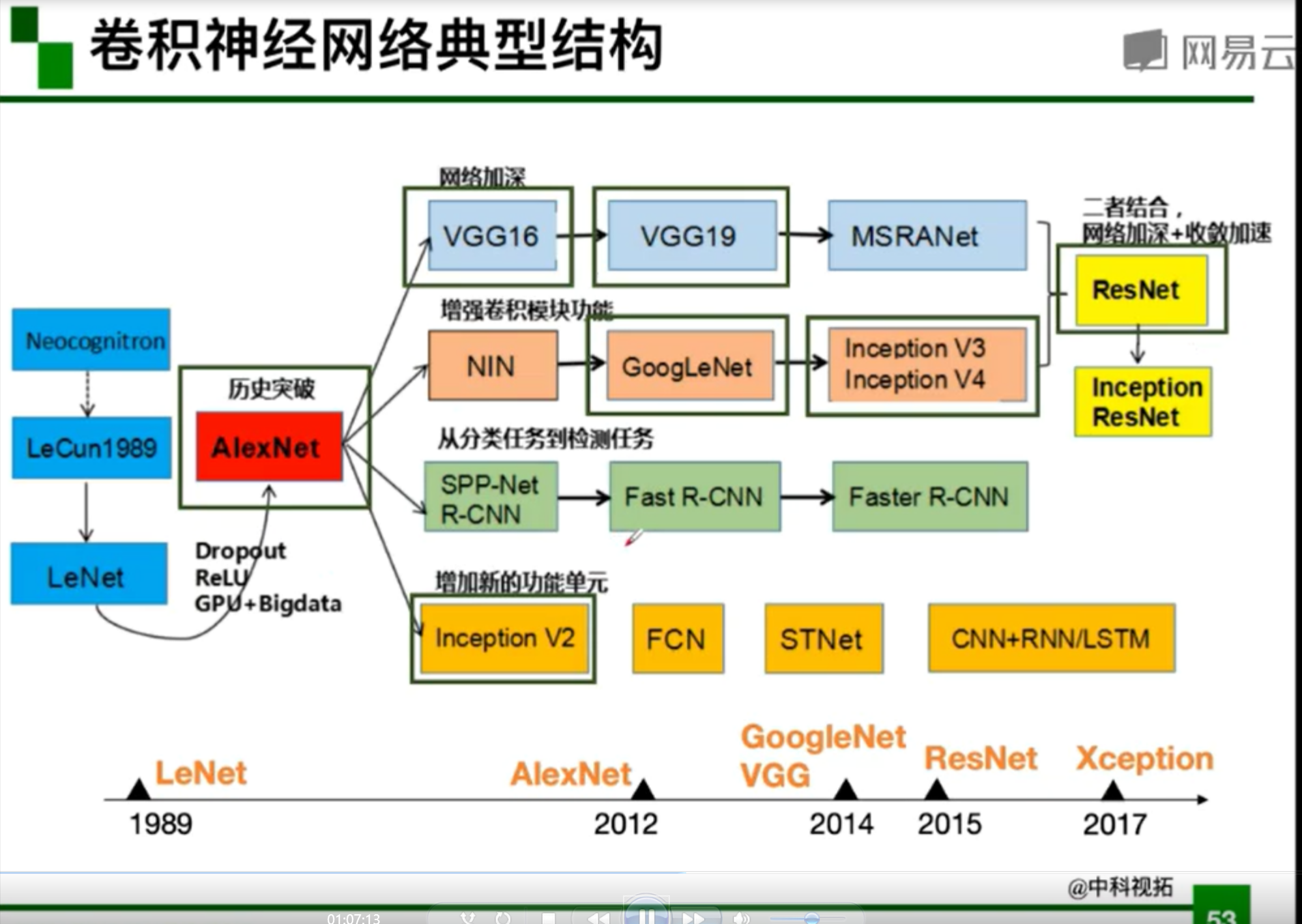
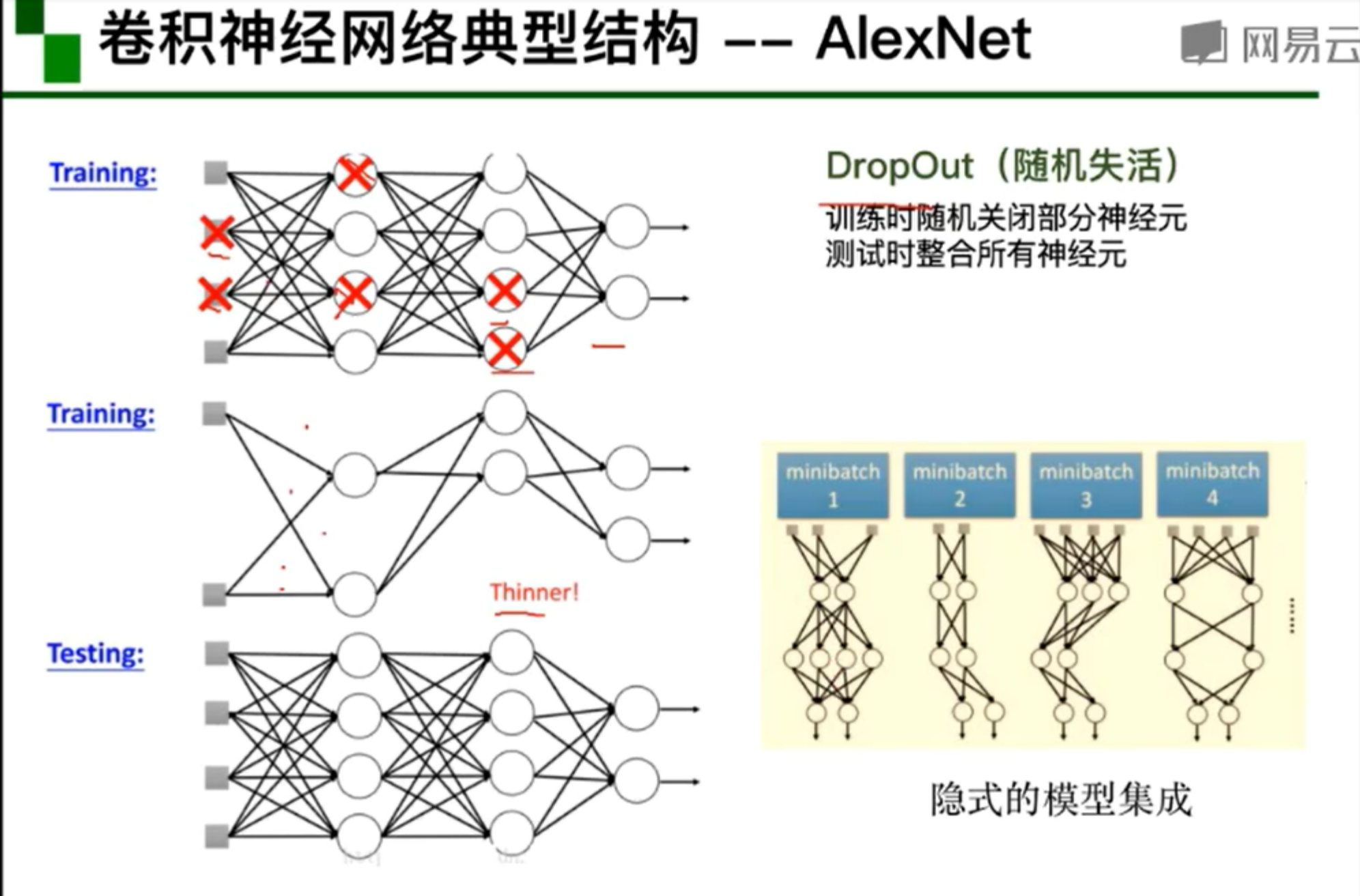
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models,transforms,datasets
import time
import json
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('Using gpu: %s ' % torch.cuda.is_available())
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
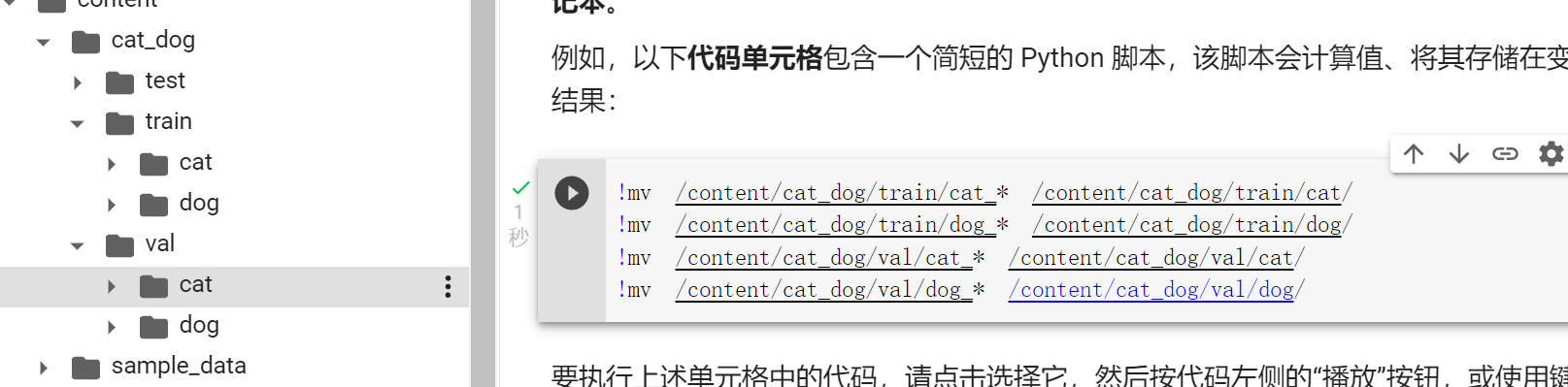
data_dir = "/content/cat_dog"
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format)
for x in ['train', 'val']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'val']}
dset_classes = dsets['train'].classes
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=128, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
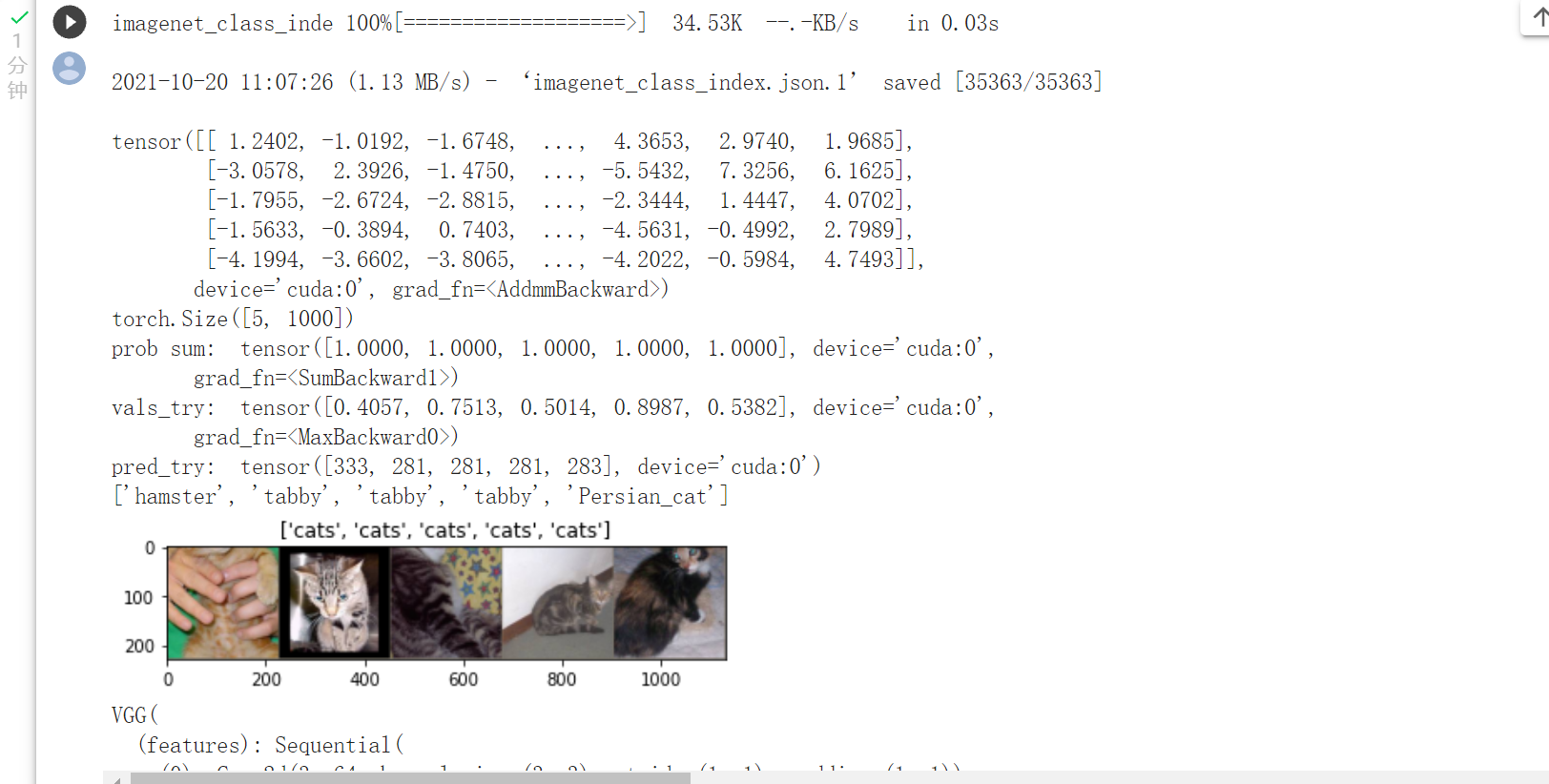
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
model_vgg = models.vgg16(pretrained=True)
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
lr = 0.001
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(), lr=lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
max_acc = 0
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
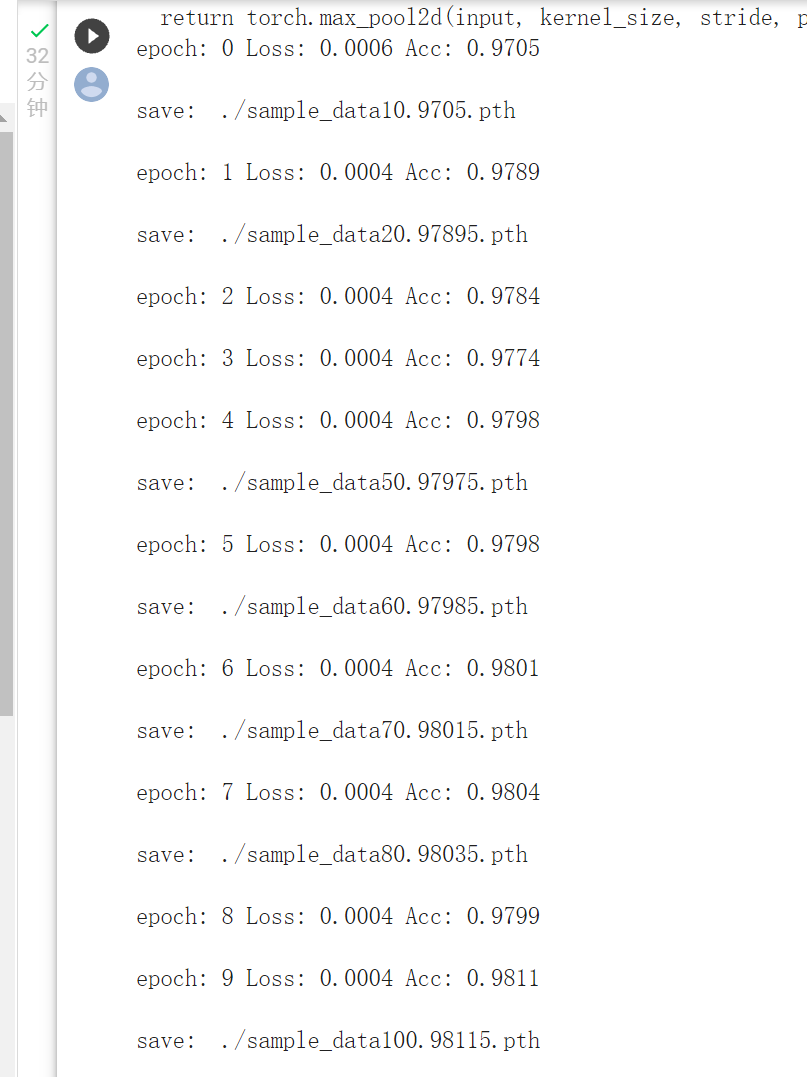
print('epoch: {:} Loss: {:.4f} Acc: {:.4f}\n'.format(epoch,epoch_loss, epoch_acc))
if epoch_acc > max_acc:
max_acc = epoch_acc
path = './sample_data' + str(epoch+1) + '' + str(epoch_acc) + '' + '.pth'
torch.save(model, path)
print("save: ", path,"\n")
train_model(model_vgg_new, loader_train, size=dset_sizes['train'], epochs=10,
optimizer=optimizer_vgg)
def test_model(model,dataloader,size):
model.eval()
predictions = np.zeros(size)
all_classes = np.zeros(size)
all_proba = np.zeros((size,2))
i = 0
running_loss = 0.0
running_corrects = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
_,preds = torch.max(outputs.data,1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
predictions[i:i+len(classes)] = preds.to('cpu').numpy()
all_classes[i:i+len(classes)] = classes.to('cpu').numpy()
all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy()
i += len(classes)
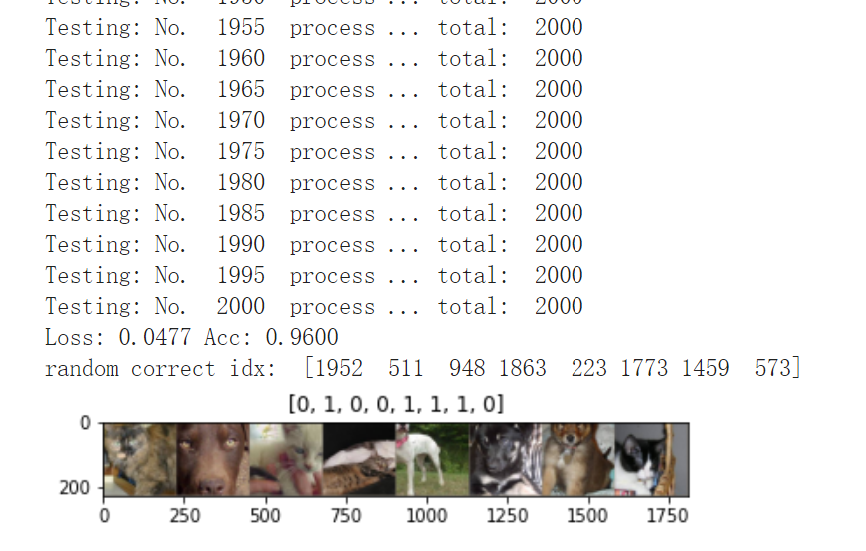
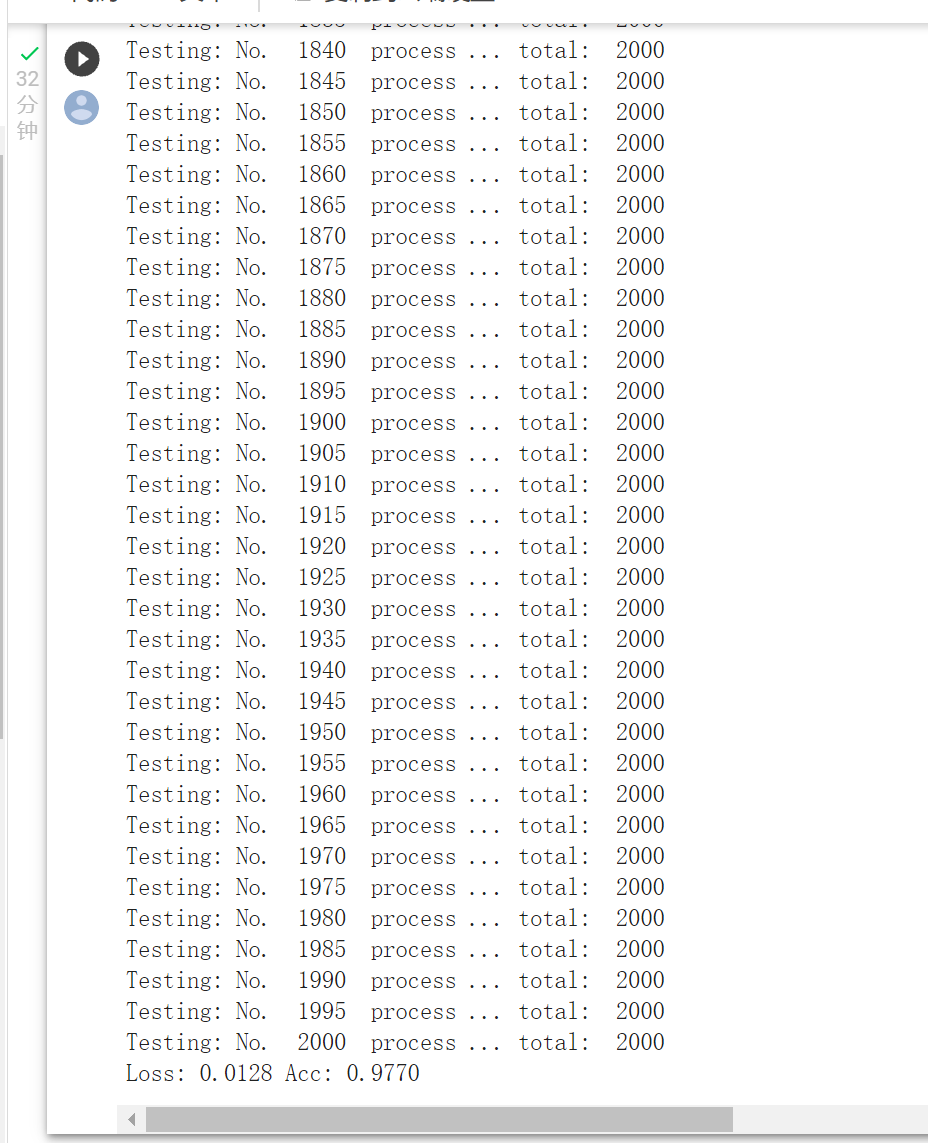
print('Testing: No. ', i, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))
return predictions, all_proba, all_classes
predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])
|











 求这个玩意儿 x,y的整数解形式。👴一看,这不就重要不等式吗,答案很显然。
求这个玩意儿 x,y的整数解形式。👴一看,这不就重要不等式吗,答案很显然。